 Tengo que demostrarle a la Vida... que ella puede hacer sobre mi lo que quiera... pero que no es lo importante lo que la Vida va a hacer con mi vida... sino que lo importante... sera lo que yo hago... con lo que la Vida me hace...
Tengo que demostrarle a la Vida... que ella puede hacer sobre mi lo que quiera... pero que no es lo importante lo que la Vida va a hacer con mi vida... sino que lo importante... sera lo que yo hago... con lo que la Vida me hace...
martes, junio 30, 2009
Vida
Tengo que demostrarle a la Vida... que ella puede hacer sobre mi lo que quiera... pero que no es lo importante lo que la Vida va a hacer con mi vida... sino que lo importante... sera lo que yo hago... con lo que la Vida me hace...
jueves, junio 25, 2009
Conocer memoria soportada por un equipo

Recientemente me preguntaba un compañero del Instituto cómo saber el tipo de memoria válida para su portatil.
La respuesta obvia era decirle que para saberlo lo mejor era abrir el equipo y mirar las pastillas de memoria que trae de fábrica.
Por fortuna existe una solución más sencilla y segura que no requiere utilizar el destornillador ![]()
Vía commandline-fu me topé con un comando (dmidecode) que permite conocer las características de la memoria soportada por nuestro ordenador.
Basta con lanzar desde la terminal un
sudo dmidecode 5,15
como respuesta obtendremos una salida similar a
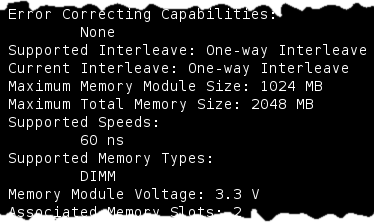
Entre otros datos obtendremos:
- Tipo de memoria (en mi caso DIMM)
- Voltaje de la memoria (3.3V en el ejemplo)
- Memoria total soportada por el equipo (en mi caso 2GB
 )
) - Velocidad de la memoria (60ns en el ejemplo)
- Si la memoria es (o no) entrelazada
- …
Completa documentación y sin necesidad de abrir el equipo ![]()
domingo, junio 14, 2009
Errare humanum est
Cometer errores es de humanos, pero para cagarla bien necesitas la contraseña de root
Un linuxero
Muchas veces lo oímos, 'ah! pero tu eres un "linuxero" de esos'. Pero que es exactamente eso de un linuxero nadie lo sabe. En principio, alguien a quien le gusta Linux y lo usa. Pero que lo diferencia de un usuario de un sistema operativo normal (llámese ventanas, manzanas o playstation ) que lo utiliza por conveniencia (entiende que es la única forma de interactuar con la máquina).
) que lo utiliza por conveniencia (entiende que es la única forma de interactuar con la máquina).
Desde mi punto de vista un linuxero es una persona:
- con inquietudes informáticas y ganas de aprender
- que participa activamente en grupos de usuarios, listas de correo, foros y comunidades
- a quien no le importa compartir conocimientos (pero no le preguntes algo que aparece en los resultados de google)
- que hace uso de determinado software (libre, open source) también por razones ideológicas
- que desea tener un completo control sobre su máquina
- que se preocupa por las licencias del software que usa
- que es consciente de que el software de Microsoft no es gratuito, ni mejor, y además nadie puede saber, excepto la compañía, que es lo que hace con exactitud
- que NO reinicia el PC cada vez que instala algún dispositivo
- que tampoco soluciona los problemas del PC reiniciando
- que NO formatea el disco duro de forma periódica
- que si encuentra un fallo en algún software libre se preocupa de avisar a los desarrolladores
- que puede trabajar con cualquier sistema Unix con pocas adaptaciones
- que es consciente que los grandes sistemas no funcionan con software ni sistemas operativos de Microsoft
- para quien el concepto de jugar con el ordenador no pasa por el uso de videojuegos
- que sabe que un sistema operativo no es lo mismo que el firmware de una videoconsola
- que en consecuencia pasa de los juegos comerciales para PC, e intenta hacer cosas útiles con el ordenador
- que piensa en el software propietario como una caja negra
- que NO tiene antivirus en su ordenador (y lo conecta a Internet!!!) y tampoco tiene virus

- que entiende que mediante las "ventanitas" no siempre se consigue hacer las cosas de manera más rápida o más fácil
- que no desea que el software que controla su ordenador y sus datos dependa de una empresa privada
- que puede hacer una copia del software libre que usa a quien quiera de forma completamente legal
- y lo más importante, que te ayudará en la medida de lo posible a adentrarte en el mundo de GNU/Linux siempre que demuestres estar realmente interesado en ello
Fin del offtopic de hoy. (Sujeto a cambios, a la espera de posibles sugerencias)
Cerrar conexiones SSH
A veces, no nos damos cuenta, y hacemos un logout de la sesión SSH, con lo cual es un fallo de seguridad, a parte del timeout que tengamos configurado, o sencillamente porque queremos matar una sesión de un usuario que no nos interesa que este logueado.
—Primero tenemos que ver quien esta conectado por ssh y esto lo podemos hacer con el comando ‘who’:
| server01:~ # who root tty1 May 6 10:23 root pts/0 May 7 07:53 (cliente.local) |
—Como podemos observar, tenemos 2 sesiones, la nuestra que es una pts y la física directamente a monitor o consola con tty.
En nuestro caso vamos a matar la sesión el tty1 con un ‘pkill’:
| server01:~ # pkill -9 -t tty1 |
—Seguidamente realizamos un ‘who’ para ver si ha saltado la sesión del tty y solo esta la nuestra que es una pts:
| server01:~ # who root pts/0 May 7 07:53 (cliente.local) server01:~ # |
Con estos sencillos pasos podemos asegurarnos de que en nuestro sistema no hay nadie y controlas las sesiones ![]()
sábado, junio 13, 2009
Matar procesos fácilmente sin conocer su PID
Procedimiento habitual
A la hora de matar procesos solemos realizar los siguientes pasos
- lanzar un ps -A (con o sin grep para localizar el proceso que nos interesa)
- anotar mentalmente el PID del proceso
- lanzar un kill -9 2345 (donde supondremos que 2345 es el PID anotado en el paso anterior)
Procedimiento simplificado
Para reducir los pasos lo único que necesitamos es tener claro el nombre del comando que deseamos eliminar (supongamos que es firefox-bin que, en ocasiones, suele quedarse pillado y se corresponde como podréis intuir al navegador web por antonomasia).
Para matarlo bastará lanzar un
kill -9 $(pidof firefox-bin)
NOTA: este procedimiento sólo funciona si existe una única instancia del proceso a eliminar; si hay varias habría que hacer un bucle pero eso lo tratamos en otra ocasión si realmente los resulta de interés.
viernes, junio 12, 2009
Riesgos y errores de los empleados según Cisco
 De acuerdo a un estudio encargado por Cisco Systems a InsightExpress, empresa dedicada a realizar investigaciones de mercado, se pudieron establecer cuales son las principales conductas que ponen en riesgo la seguridad de los datos al interior de las compañías. La investigación descubrió que a pesar de las políticas, procedimientos y herramientas de seguridad actualmente en uso, los empleados de todo el mundo exhiben conductas arriesgadas que ponen en peligro los datos personales y empresariales.
De acuerdo a un estudio encargado por Cisco Systems a InsightExpress, empresa dedicada a realizar investigaciones de mercado, se pudieron establecer cuales son las principales conductas que ponen en riesgo la seguridad de los datos al interior de las compañías. La investigación descubrió que a pesar de las políticas, procedimientos y herramientas de seguridad actualmente en uso, los empleados de todo el mundo exhiben conductas arriesgadas que ponen en peligro los datos personales y empresariales. ● Uso de aplicaciones no autorizadas: el 70% de los profesionales de TI cree que el uso de programas no autorizados fue responsable de hasta la mitad de los incidentes de pérdida de información en sus empresas.
● Uso indebido de computadoras de la empresa: el 44% de los empleados comparte dispositivos de trabajo con otras personas sin supervisión.
● Acceso no autorizado tanto físico como a través de la red: el 39% de los profesionales de TI afirmó que ha debido abordar el acceso no autorizado por parte de un empleado a zonas de la red o de las instalaciones de la empresa.
● Seguridad de trabajadores remotos: el 46% de los empleados admitió haber transferido archivos entre computadoras del trabajo y personales al trabajar desde el hogar.
● Uso indebido de contraseñas: el 18% de los empleados comparte contraseñas con sus colegas. El porcentaje aumenta al 25% en China, India e Italia.
Sin duda que aunque gran parte del peligro proviene desde redes externas (por ejemplo Internet),
los contínuos esfuerzos del personal de TI por prevenir las fugas de información dentro de las redes de la compañía se ven mermados por este tipo de comportamientos de los usuarios finales que muchas veces son causadas por ignorancia, descuido o mala intención.
Las empresas deben comenzar por evaluar la conducta de los empleados y los riesgos asociados basándose en factores tales como el país y el panorama de amenazas. Luego de acuerdo con dicha evaluación pueden diseñarse planes de educación sobre amenazas, capacitación en seguridad y procesos comerciales. Ése es el momento de realizar inversiones pertinentes en tecnología de seguridad. Esta estrategia integral es la mejor forma de lograr un nivel de seguridad sostenible.
Pueden visualizar el contenido completo de este estudio en:
* http://www.cisco.com/web/offer/em/pdfs_innovators/LATAM/data_mist_sp.pdf...
* http://www.cisco.com/web/offer/em/pdfs_innovators/LATAM/data_threat_sp.p...
Recomendaciones de seguridad para las redes inalámbricas
 El crecimiento exponencial que se ha manifestado en las redes inalámbricas en los últimos años ha traido inevitablemente dos consecuencias (hay más, pero las que nos convocan son dos).
El crecimiento exponencial que se ha manifestado en las redes inalámbricas en los últimos años ha traido inevitablemente dos consecuencias (hay más, pero las que nos convocan son dos).1) Mayores problemas de seguridad
2) Contaminación y saturación del espectro de 2.4 Ghz
Lo primero es humanamente posible de solucionar, mientras que lo segundo pareciera ser inevitable. Lo concreto es que si tomamos una serie de medidas podemos proteger nuestra red inalámbrica contra intrusos y reducir en un importante porcentaje el riesgo de ataque, intrusión, robo de datos, uso de nuestra conexión, etc.
La siguiente es una lista que dividiré en dos. La primera parte para gente que definitivamente sabe muy poco de redes wi-fi y la otra para usuarios más avanzados. La idea es restringir lo más que se pueda el acceso a nuestras redes. Mientras más barreras pongamos mejor.
Recomendaciones para la seguridad en ambientes inalámbricos:
I) Medidas que pueden tomar los usuarios inexpertos o que no saben nada de Wi-Fi:
- Apague su router o access point cuando no lo ocupe. No lo deje encendido en las noches si es que nadie lo está usando.
- Exija que su conexión tenga clave inalámbrica, Bajo ningún motivo mantenga su conexión SIN CLAVE, excepto si vive a 500 kms de un vecino cercano.
- Si su conexión tiene clave, jamás se la diga a terceros ni siquiera de forma temporal (por ejemplo un técnico que visite la casa).
- Siempre respalde su información importante en CD y guárdelos muy bien.
- Use una clave de red de tipo WPA2 de preferencia. Si su tarjeta no la soporta, utilice WPA, pero trate de nunca usar WEP si su router/access point permite usar otro tipo de cifrado.
- Habilite el control de acceso por direcciones MAC. Aunque son fáciles de clonar, esto ya supone una barrera para un supuesto atacante.
- Deshabilite servicios innecesarios en su router, como por ejemplo SNMP, Telnet, SSH, etc.
- Si su router tiene una interfaz de configuración Web, deshabilite su acceso vía inalámbrica de tal manera que pueda ser accesible solo por cable.
- Cambie los puertos por defecto de su router. Si la configuración se revisa en http://192.168.1.1:8080 cambie el 8080 por un número mayor (hasta 65535).
- Desactive la opción de SSID Broadcasting si es posible. Esto quiere decir que el nombre de la red (SSID, Service Set IDentifier) no será visible en el aire y quien quiera conectarse a su red necesitará conocer el nombre.
- Desactive la opción de DHCP, entregue direcciones IP manualmente a la red LAN.
- El rango de direcciones IP LAN de muchos equipos es: 192.168.x.x. Cambienlo por un número menos adivinable, por ejemplo 90.0.0.0 /24.
- Si está dentro de las posibilidades considere usar un servidor RADIUS para la autenticación de usuarios de la red.
- Usar VPN con cifrado para conectarse a la red Wi-Fi es una buena idea. Hay varios routers que soportan conexiones VPN ya sea PPTP o IPSec.
- Cambie regularmente sus claves de conexión WI-Fi. Regularmente significa al menos una vez al mes.
- Guarde muy bien el usuario y password de administración del router Wi-Fi.
- Para las contraseñas (y también usuarios si lo prefiere) NO UTILICE palabras comunes, por ejemplo admin25, misuperpassword00, password1, etc. Un buen ejemplo de clave sería "_1aR3@_BAN_48. Idealmente mezclar MaYÚsCuLas con minúsculas, números y caracteres poco comunes.
- No ponga su router /access point cerca de: Un horno microondas, un teléfono inalámbrico de 2.4 Ghz. Estos producen interferencia en la señal.
- Cambie regularmente el SSID de su red y NO PONGA COMO NOMBRE ALGO MUY DESCRIPTIVO, por ejemplo: WIFI_DEPARTAMENTO_1023_EDIFICIO_AZUL.
- Por último, pero no menos importante, antes de levantar su conexión Wi-Fi es buena idea hacer un scanning de las redes existentes en el lugar, sus niveles de señal y ruido para ocupar el canal menos saturado. Generalmente los routers vienen con el canal 6 por defecto y quienes administran estos equipos los dejan tal cual, por lo tanto es válido suponer que siempre vamos a encontrar alguna red en ese canal.
Hardening de servidores Linux y Windows. Mejorando la seguridad.
 Una de las tareas más laboriosas de un buen administrador de sistemas es, luego de instalar un nuevo servidor o querer mejorar uno existente, comenzar la tarea de optimizar la seguridad del sistema operativo instalado. Sea Windows Server, Linux o algún otro Unix, siempre hay que hacerle unos pequeños ajustes (tweaks) ya que salvo contadas excepciones (OpenBSD y algún otro por ahí) las configuraciones por defecto que traen son bastante pobres en cuanto a seguridad y dejarlas sin modificar puede ser una puerta de entrada para los intrusos que quieran lograr acceso al servidor.
Una de las tareas más laboriosas de un buen administrador de sistemas es, luego de instalar un nuevo servidor o querer mejorar uno existente, comenzar la tarea de optimizar la seguridad del sistema operativo instalado. Sea Windows Server, Linux o algún otro Unix, siempre hay que hacerle unos pequeños ajustes (tweaks) ya que salvo contadas excepciones (OpenBSD y algún otro por ahí) las configuraciones por defecto que traen son bastante pobres en cuanto a seguridad y dejarlas sin modificar puede ser una puerta de entrada para los intrusos que quieran lograr acceso al servidor. Este procedimiento de tweaking, llamado comúnmente hardening, muchas veces hace la diferencia entre un sistema con un alto nivel de seguridad a uno vulnerable y fácil de "hackear"...
Para facilitar las cosas se han creado herramientas que ayudan a automatizar el hardening de servidores con lo que se puede tener una visión mucho más profunda de cuanto puede llegar a ser vulnerado un sistema en la realidad y donde están las brechas de seguridad que permitirían el ingreso de un atacante ilegítimo.
Para servidores Windows (2000, 2003 y 2008) está IPFront. IPFront ayuda a crear algunos scripts para ejecutar en modo batch. Creado por Hernán M. Racciatti se presenta como una buena alternativa para obtener un enfoque más completo de qué nivel de inseguridad está ofreciendo la máquina Windows Server donde se corre algún servicio importante. Aunque existan herramientas complementarias para esto (como las GPO), nunca está demás consultar IPFront para tener una segunda opinión.
Por otro lado, para Linux hay mayor variedad de software de hardening de muy buena calidad como Bastille Linux y Lynis, aunque este último es solamente un "consejero" que advierte lo que se puede mejorar e indica como hacerlo.
Grsecurity es una aplicación que trabaja a modo de parche de kernel e instala algunas configuraciones de seguridad que evitan, entre otras cosas, que por ejemplo se ejecute código arbitrario, se eleven privilegios sin autorización, etc. Funciona muy parecido a SELinux pero ambos pueden complementarse con un poco de trabajo extra.
Más información de Hardening en Linux:
1.- http://www.linux-sec.net/Harden/howto.gwif.html
2.- http://www.howtoforge.com/hardening-the-linux-kernel-with-grsecurity-debian
Hardening para Windows: http://www.esemanal.com.mx/articulos.php?id_sec=5&id_art=4499
Via: http://www.seguridad-informatica.cl/web/content/hardening-de-servidores-linux-y-windows-mejorando-la-seguridad
Acceder a sistemas Linux y Windows sin contraseñas de usuarios.
En seguridad informática hay un principio básico: “El acceso físico a la máquina es acceso total a esta". Y con Kon-Boot podemos demostrar este principio, ya que nos permite acceder a sistemas Linux y Windows sin contraseñas de usuarios.
Kon-Boot no es intrusiva ya que no realiza ninguna modificación en el sistema que pueda ser detectada. Su funcionamiento se basa en parchear el núcleo del sistema cuando se carga en memoria al arrancar el equipo, anular todos los procesos de autentificación y abrir un acceso al sistema en modo root/Administrador.
Kon-Boot esta testeado en los siguientes sistemas:
- Windows:
- Windows Server 2008 Standard SP2 (v.275).
- Windows Vista Business SP0.
- Windows Vista Ultimate SP1.
- Windows Vista Ultimate SP0.
- Windows Server 2003 Enterprise.
- Windows XP.
- Windows XP SP1.
- Windows XP SP2.
- Windows XP SP3.
- Windows 7.
- Linux:
- Gentoo 2.6.24-gentoo-r5.
- Ubuntu 2.6.24.3-debug.
- Debian 2.6.18-6-686.
- Fedora 2.6.25.9-76.fc9.i686.
Se puede arrancar desde CD o desde un disquete.
Más información y descarga de Kon-Boot:
http://www.piotrbania.com/all/kon-boot/
Visto en http://vtroger.blogspot.com/
Revista PUNTO SEGURIDAD # 1

Revista .Seguridad (Punto Seguridad), es un esfuerzo de la UNAM realiza a través de la Dirección General de Servicios de Cómputo Académico para hacer llegar contenidos de seguridad informática dirigida al usuario no técnico y a todo aquél usuario relacionado con las tecnologías de la información y comunicaciones.
.Seguridad es un esfuerzo de diversas áreas que conforman la DGSCA en el que organizaciones y usuarios encontrarán información que le guíe y que a su vez le prevenga ante principales amenazas latentes.
El número 1 aborda el tema de Códios Maliciosos, los artículos que se presentan son los siguientes.
- CÓDIGOS MALICIOSOS
- CÓDIGOS MALICIOSOS EN DISPOSITIVOS MÓVILES
- CONFICKER EN MÉXICO
- RECOMENDACIONES AL ELEGIR UNA SUITE DE SEGURIDAD
- TIPS DE SEGURIDAD
Responsable de Seguridad de la Información, una figura indispensable en las empresas
El constante manejo de información en las empresas hace necesaria la labor de un CISO (Chief Information Security Officer) que gestione y controle todos los datos de la organización. Algunas entidades instan incluso a la incorporación de estos responsables de la seguridad de la información a los equipos directivos. De todo ello se hablará en la V Jornada Internacional de Seguridad que organiza ISMS Forum en Madrid.
Porque los extravíos de información en las empresas pueden suponer pérdidas millonarias, se hace cada vez más imprescindible contar con un CISO (Chief Information Security Officer) o Responsable de Seguridad de
Y es especialmente relevante su labor en las entidades financieras, un sector castigado frecuentemente por el robo de identidades, spam y phishing. Así lo pone de manifiesto el Informe anual sobre seguridad en instituciones financieras que presentó a comienzos de año la consultora Deloitte. Del documento se extrae, además, la preocupación por la escasez de profesionales especializados en materia de seguridad.
Estos profesionales suelen ejercer con varios años de experiencia y un sólido conocimiento en actividades de planificación, auditoría y gestión, así como en el manejo de contratos y negociación de proveedores en el ámbito de las Tecnologías de
De hecho, y aunque sea un perfil bastante novedoso, existen numerosos programas en universidades y escuelas tanto a nivel universitario como de postgrado en seguridad de tecnologías de la información, con contenidos que van desde los sistemas de gestión de seguridad, al análisis de riesgos, la seguridad en las comunicaciones y operaciones o el control de accesos.
Con el propósito de analizar las competencias y habilidades de estos profesionales se celebra el próximo jueves 28 de mayo
Bajo el nombre “La organización de la seguridad: el laberinto del CISO”, el encuentro analizará cuál es la estructura óptima y la gestión de
“El Responsable de Seguridad tiene que saber conjugar la aplicación de las nuevas tecnologías reduciendo, al mismo tiempo, el riesgo de fugas de información”, explica Marie-Claire Pfeifer, consejera delegada de Giga Trust en España, miembro asociado de ISMS Forum. Es una de las empresas que apuestan por la incorporación de los responsables de seguridad a los equipos directivos de las organizaciones. “Es importante que debatamos sobre los modelos de organización en la gestión de la seguridad de la información con la incorporación del CISO como parte activa de los equipos directivos”.
Serán partícipes de este tema Víctor Izquierdo, director del Instituto de Tecnologías de
Fuente: www.aprendemas.com
Link relacionado:
- V Jornada Internacional de Seguridad de ISMS Forum
Autopsy Forensic Browser: guía paso a paso
Los chicos de Sans Forensics han publicado una guía con la que manejar el frontal de análisis forense Autopsy será prácticamente coser y cantar.

Autopsy es un frontal Web que permite realizar operaciones de análisis forense sirviendo como interfaz gráfico del popular juego de herramientas forenses The Sleuth Kit (TSK). TSK es un referente en el mundo del análisis forense mediante la línea de mandatos, y que permite a los investigadores lanzar auditorías forenses no intrusivas en los sistemas a investigar. Probablemente la mayor concentración de uso de TSK la tengamos en dos tipos de análisis: análisis genérico de sistemas de archivos y líneas temporales de ficheros.
TSK tiene una larga historia, ya que emplea el mismo código que The Coroner's Toolkit (TCT), de Wietse Venema y Dan Farmer, y puede ser empleado en plataformas Linux, Mac OS X, CYGWIN, OpenBSD, FreeBSD y Solaris. Es posible su instalación en Windows, aunque es poco frecuente, ya que la mayoría de suites forenses suelen estar disponibles como live CDs de Linux, aprovechando no sólo la abundancia de aplicaciones libres, sino la integración de las mismas.
Para facilitar la labor de los investigadores, TSK y Autopsy suelen ir de la mano, lo que hace que no sea necesario invocar constantemente la línea de comandos cuando queremos inspeccionar una imagen. Un paso a paso para aprender los conceptos básicos de este frontal puede resultar bastante útil para principiantes. En este ejemplo se describe cómo abrir un caso y cómo vincular una imagen de un sistema a investigar al mismo. También se muestra cómo acceder a los procedimientos básicos de investigación (líneas temporales de actividad, verificación de la integridad de una imagen, secuenciador de eventos ... etc.)
Pueden ojear el paso a paso en este enlace.
Fuente: www.sahw.comAnálisis forense, ¿Cómo investigar un incidente de seguridad?
 A pesar de las barreras de protección erigidas para salvaguardar los activos de información, los incidentes de seguridad se siguen produciendo. Estar preparado para reaccionar ante un ataque es fundamental. Una de las fases más importantes de la respuesta a incidentes consiste en la investigación del incidente para saber por qué se produjo la intrusión, quién la perpetró y sobre qué sistemas. Esta investigación se conoce como análisis forense y sus características más destacadas serán explicadas en este artículo.
A pesar de las barreras de protección erigidas para salvaguardar los activos de información, los incidentes de seguridad se siguen produciendo. Estar preparado para reaccionar ante un ataque es fundamental. Una de las fases más importantes de la respuesta a incidentes consiste en la investigación del incidente para saber por qué se produjo la intrusión, quién la perpetró y sobre qué sistemas. Esta investigación se conoce como análisis forense y sus características más destacadas serán explicadas en este artículo. Un plan de respuesta a incidentes ayuda a estar preparado y a saber cómo se debe actuar una vez se haya identificado un ataque. Constituye un punto clave dentro de los planes de seguridad de la información, ya que mientras que la detección del incidente es el punto que afecta a la seguridad del sistema, la respuesta define cómo debe reaccionar el equipo de seguridad para minimizar los daños y recuperar los sistemas, todo ello garantizando la integridad del conjunto.
El plan de respuesta a incidentes suele dividirse en varias fases, entre las que destacan:
1) respuesta inmediata, para evitar males mayores, como reconfigurar automáticamente las reglas de los cortafuegos o inyectar paquetes de RESET sobre conexiones establecidas;
2) investigación, para recolectar evidencias del ataque que permitan reconstruirlo con la mayor fidelidad posible;
3) recuperación, para volver a la normalidad en el menor tiempo posible y evitar que el incidente se repita de nuevo; y
4) creación de informes, para documentar los datos sobre los incidentes y que sirvan como base de conocimiento con posterioridad, para posibles puntos de mejora y como información para todos los integrantes de la organización. De manera adicional, se hacen necesarios los informes por posibles responsabilidades legales que pudieran derivarse.
Articulo completo...ISO/IEC 27000:2009 - Ultimo integrante de la Familia ISO 27000
ISO/IEC 27000:2009
El ISO/IEC 27000, contiene los fundamentos y vocabulario para:
El ISO/IEC 27000, contiene los fundamentos y vocabulario para:
* Dar una visión panorámica de los estándares ISO 27000, explicando como son usados de manera colectiva, para planear, implementar, certificar y operar un SGSI.
* Detallar definiciones para los términos relacionados con la seguridad de información en la manera que son usados en los estándares de la familia ISO 27000.
Descargar el Documento
Visto en eficienciagerencial.com
The objectives of ISO/IEC 27000:2009 are to provide terms and definitions, and an introduction to the ISMS family of standards that:
- define requirements for an ISMS and for those certifying such systems;
- provide direct support, detailed guidance and/or interpretation for the overall Plan-Do-Check-Act (PDCA) processes and requirements;
- address sector-specific guidelines for ISMS; and
- address conformity assessment for ISMS.

Via: http://seguridad-informacion.blogspot.com/
La comunicación es un asunto de capas
¿Alguna vez has tratado de entender cómo es ese asunto de las capas del modelo OSI o del conjunto de protocolos TCP/IP? Algunos maestros, en lugar de ayudar a comprenderlo sólo lograron confundir a más de cuatro, estoy seguro.

 Y al final sigue quedando la gran incógnita: ¿qué función tienen las capas en un modelo como OSI o TCP/IP? Esto lo escucho una y otra vez cada vez que doy un curso de redes y en realidad es algo muy simple. La gente encargada de definir el modelo pensó en una manera de representar que dentro de una comunicación intervienen una serie de elementos que, si bien son diferentes entre sí, se interrelacionan de una manera tal que pueden conseguir que una transmisión de datos se lleve a cabo. El concepto de capas es simplemente una forma de representar la individualidad de cada tarea en la comunicación y cómo se relaciona con otras tareas para lograr una colaboración de todo el conjunto.
Y al final sigue quedando la gran incógnita: ¿qué función tienen las capas en un modelo como OSI o TCP/IP? Esto lo escucho una y otra vez cada vez que doy un curso de redes y en realidad es algo muy simple. La gente encargada de definir el modelo pensó en una manera de representar que dentro de una comunicación intervienen una serie de elementos que, si bien son diferentes entre sí, se interrelacionan de una manera tal que pueden conseguir que una transmisión de datos se lleve a cabo. El concepto de capas es simplemente una forma de representar la individualidad de cada tarea en la comunicación y cómo se relaciona con otras tareas para lograr una colaboración de todo el conjunto.En esta ocasión, como estoy de buen humor (como casi siempre ;)), les voy a platicar una alegoría para intentar explicar un aspecto fundamental en las comunicaciones entre dos equipos en una red de datos que usa TCP/IP. Después de contar la historia, trataré de aplicarla al concepto de comunicación del que estamos hablando, tengan paciencia.
La capa de Aplicación, en el origen
Yo vivo en Monterrey, México, y tengo un amigo, Guillermo Alegría (la versión mexicana de Bill Joy :D), que vive en la Ciudad de México. Mi amigo me ha pedido ayuda porque quiere aprender UNIX, así que pensé en enviarle unos manuales que tengo por ahí guardados.
La capa de Transporte, en el origen
Como son varios libros y quiero asegurarme de que mi amigo los reciba, he pensado que la mejor manera de enviarlos será uno a la vez, y una vez que tenga la confirmación de que recibió el primer libro, le envío el segundo y así sucesivamente (soy un poco desconfiado, por eso mejor me aseguro de que los va recibiendo, uno a la vez). Para que no se maltraten, envuelvo cada libro en un paquete.
La capa de Internet, en el origen
Por supuesto que para enviar un paquete necesito escribir el nombre y la dirección de Guillermo, y también la mía en caso de que mi amigo ya no viviera en ese domicilio y tuvieran que devolverme el paquete (no puedo darme el lujo de perder un libro de UNIX). Mi amigo vive en la célebre calle Chopo, en el número ocho, y así lo escribo en el paquete.
La capa de Enlace de Datos, en el origen
Llego a la empresa de mensajería, una de confianza. El encargado observa el paquete y me pregunta por qué medio quiero enviarlo: "¿Por avión o por carretera?" -me pregunta. Me interesa que mi amigo comience a estudiar cuanto antes, pero no tanto como para pagar la diferencia de un envío aéreo. "Por carretera" -le respondo.
El medio físico
Y ahí va el libro, viajando por carretera hasta la Ciudad de México. Diez horas de camino. En México encuentran mucho tráfico, como siempre, lo que retrasa el envío dos horas más. Ni hablar, todo sea en aras del saber.
La capa de Enlace de Datos, en el destino
Al fin la camioneta de reparto llega a Chopo 8, se aseguran de estar en el domicilio indicado y tocan el timbre. Mi amigo abre la puerta y se alegra de recibir el envío. A simple vista el paquete parece estar en buenas condiciones, de lo contrario, si llegara abierto por ejemplo, no lo aceptaría y me sería devuelto, o posiblemente sí lo recibiría, haciendo la observación pertinente al que lo entrega.
La capa de Internet, en el destino
Le preguntan a mi amigo: "¿Es usted Guillermo Alegría?", y él responde afirmativamente, por supuesto, y le entregan el paquete.
La capa de Transporte, en el destino
Le dan a firmar un acuse de recibo, porque recuerden que yo quería asegurarme de que recibiera el paquete, así que pedí que por cada paquete que él recibiera, firmara un recibo indicando que efectivamente tenía ya en su poder el paquete, así yo sabría que podría enviar el siguiente libro con mayor confianza. Mi amigo ya no puede esperar, le quita la envoltura al libro y observa que es el volumen 1, lo que quiere decir que seguramente deberá esperar más libros como ese. Si en el siguiente envío yo le mandara el volumen 3, seguramente él me mandaría a avisar que le faltó el volumen 2 y que no puede saltarse del 1 al 3, que necesita el 2. Al menos eso haría yo.
La capa de Aplicación, en el destino
Sentado cómodamente en su sillón, con un refresco y unas frituras, mi amigo Memo (es que así le decimos en México a los que se llaman Guillermo) se dispone a leer el libro de UNIX y se da cuenta de que podrá hacer muchas cosas ahora que aprenda a usarlo. Sólo espero que un día de éstos no me diga que ejecutó "rm -r /", siendo root. ;-)
¿Y qué tiene que ver esto con TCP/IP?
Mucho. TCP/IP es un conjunto de protocolos (reglas de comunicación) que tienen su propia función y que en conjunto pueden llevar a cabo la comunicación entre, al menos, dos dispositivos en una red. La división en capas nos ayuda a entender que en la capa de Aplicación se preparan los datos que serán enviados desde una Aplicación X a una Aplicación Y en otro dispositivo; como los datos que se envían seguramente son muchos, la capa de Transporte puede segmentar dichos datos en segmentos o datagramas que sean más fáciles de enviar, por tener un tamaño más manejable para los dispositivos de red. Como posiblemente sean varios segmentos de datos, se enumeran para que, una vez que lleguen a su destino, el destinatario (el que los recibe) sepa que han llegado todos los datos o si tal vez faltó alguno para pedir que se envíe nuevamente. Ahora bien, ninguna comunicación confiable será completa si no hay un adecuado direccionamiento, o si no se conoce el domicilio o dirección de quien recibirá los datos, y es precisamente la capa de Internet la encargada de identificar en cada paquete de datos la dirección de quien envía y de quien recibirá dichos datos. Una vez que ya se tienen listos los datos, en la capa de Enlace de Datos se prepara una trama (frame) para que los datos puedan ser enviados por algún medio físico, usando un cable, por ejemplo, o a través de ondas por el aire. Como cada medio es diferente y exige diferentes tipos de controles, las tramas se preparan para cada medio en particular, de acuerdo a los estándares.
Cuando los datos llegan al destinatario ocurre la operación contraria, pues las tramas llegan por un medio físico, y cada protocolo de cada capa va tomando la información que requiere de su contraparte que envió los datos. Por ejemplo, la capa de Enlace de Datos se asegura de que la trama realmente vaya dirigida a ese dispositivo físico de la red y pasa el paquete a la capa de Internet para que haga lo mismo; en la capa de Internet se verifica que la dirección de destino sea efectivamente la actual y se pasa a la capa de Transporte para que verifique a su vez que el segmento forma parte de la secuencia esperada y, en muchos casos, preparar una confirmación de haber recibido los datos, para que se envíen más. Al final, los datos son colocados en orden y pasados a la capa de Aplicación, que hará que sean presentados o recibidos por la Aplicación Y de una manera legible, ya sin todo el "empaque" que se colocó en los datos al ser enviados.
Obviamente esta es una explicación muy simplificada de lo que realmente ocurre. No hablé, por ejemplo, del famoso three-way handshake para TCP, por ejemplo, ni de otras características igualmente importantes, pero para eso hay muy buenos libros y otros recursos de consulta. Este es solamente mi sencilla aportación para tratar de explicar algo como a mi me hubiera gustado que me lo explicaran.
Fin de la transmisión.
Vía: 
 http://www.romeosanchez.com/
http://www.romeosanchez.com/
http://www.romeosanchez.com/Frase
Y si un amigo te hace mal, di: Te perdono lo que me has hecho a mi; pero el que te hayas hecho eso a ti - ¡como podria yo perdonarlo!
Nietzsche
jueves, junio 11, 2009
Referencia de Comandos Unix-Linux
La siguiente lista de comandos pretende ser de utilidad como referencia rapida para utilizar comandos de sistema. Se ha agrupado en dos: los comandos de sistema corrientes y los relacionados con la administracion.
Comando
ls
Descripción: =list. listar contenido de directorios.
Ejemplos: ls, ls -l, ls -fl, ls --color
cp
Descripción: =copy. copiar ficheros/directorios.
Ejemplos:cp -rfp directorio /tmp, cp archivo archivo_nuevo
rm
Descripción: =remove. borrar ficheros/directorios.
Ejemplos: rm -f fichero, rm -rf directorio, rm -i fichero
mkdir
Descripción: =make dir. crear directorios.
Ejemplos: mkdir directorio
rmdir
Descripción: =remove dir. borrar directorios, deben estar vacios.
Ejemplos: rmdir directorio
mv
Descripción: =move. renombrar o mover ficheros/directorios.
Ejemplos: mv directorio directorio, mv fichero nuevo_nombre, mv fichero a_directorio
date
Descripción: gestion de fecha de sistema, se puede ver y establecer.
Ejemplos: date, date 10091923
history
Descripción: muestra el historial de comandos introducidos por el usuario.
Ejemplos: history | more
more
Descripción: muestra el contenido de un fichero con pausas cada 25 lineas.
Ejemplos: more fichero
grep
Descripción: filtra los contenidos de un fichero.
Ejemplos:cat fichero | grep cadena
cat
Descripción: muestra todo el contenido de un fichero sin pausa alguna.
Ejemplos: cat fichero
chmod
Descripción: cambia los permisos de lectura/escritura/ejecucion de ficheros/directorios.
Ejemplos: chmod +r fichero, chmod +w directorio, chmod +rw directorio -R, chmod -r fichero
chown
Descripción: =change owner. cambia los permisos de usuario:grupo de ficheros/directorios.
Ejemplos: chown root:root fichero, chown pello:usuarios directorio -R
tar
Descripción: =Tape ARchiver. archivador de ficheros.
Ejemplos: tar cvf fichero.tar directorio , tar xvf fichero.tar, tar zcvf fichero.tgz directorio, tar zxvf fichero.tgz
gunzip
Descripción: descompresor compatible con ZIP.
Ejemplos: gunzip fichero
rpm
Descripción: gestor de paquetes de redhat. Para instalar o actualizar software de sistema.
Ejemplos: rpm -i paquete.rpm, rpm -qa programa, rpm --force paquete.rpm, rpm -q --info programa
mount
Descripción: montar unidades de disco duro, diskette, cdrom.
Ejemplos: mount /dev/hda2 /mnt/lnx, mount /dev/hdb1 /mnt -t vfat
umount
Descripción: desmontar unidades.
Ejemplos: umount /dev/hda2, umount /mnt/lnx
wget
Descripción: programa para descargar ficheros por http o ftp.
Ejemplos: wget http://www.rediris.es/documento.pdf
lynx
Descripción: navegador web con opciones de ftp, https.
Ejemplos: lynx www.ibercom.com, lynx --source http://www.ibercom.com/script.sh | sh
ftp
Descripción: cliente FTP.
Ejemplos: ftp ftp.ibercom.com
whois
Descripción: whois de dominios.
Ejemplos: whois ibercom.com
who
Descripción: muestra los usuarios de sistema que han iniciado una sesion.
Ejemplos: who, w, who am i
mail
Descripción: envio y lectura de correo electronico.
Ejemplos: mail pepe@ibercom.com <>
sort
Descripción: ordena el contenido de un fichero.
Ejemplos: cat /etc/numeros | sort, ls | sort
ln
Descripción: =link. para crear enlaces, accesos directos.
Ejemplos: ln -s /directorio enlace
tail
Descripción: muestra el final (10 lineas) de un fichero.
Ejemplos:tail -f /var/log/maillog, tail -100 /var/log/maillog | more
head
Descripción: muestra la cabecera (10 lineas) de un fichero.
Ejemplos: head fichero, head -100 /var/log/maillog | more
file
Descripción: nos dice de que tipo es un fichero.
Ejemplos: file fichero, file *
Comandos de administracion
sysctl
Descripción: Configurar los paràmetros del kernel en tiempo de ejuecución.
Ejemplos: sysctl -a
ulimit
Descripción: muestra los limites del sistema (maximo de ficheros abiertos, etc..)
Ejemplos: ulimit
adduser
Descripción: añadir usuario de sistema.
Ejemplos: adduser pepe, adduser -s /bin/false pepe
userdel
Descripción: = eliminar usuario de sistema
Ejemplos: userdel pepe
usermod
Descripción: = modificar usuario de sistema
Ejemplos: usermod -s /bin/bash pepe
df
Descripción: = disk free. espacio en disco disponible. Muy util.
Ejemplos: df, df -h
uname
Descripción: =unix name. Informacion sobre el tipo de unix en el que estamos, kernel, etc.
Ejemplos: uname, uname -a
netstat
Descripción: la informacion sobre las conexiones de red activas.
Ejemplos: netstat, netstat -ln, netstat -l, netstat -a
ps
Descripción: =proccess toda la informacion sobre procesos en ejecucion.
Ejemplos: ps, ps -axf, ps -A, ps -auxf
free
Descripción: muestra el estado de la memoria RAM y el SWAP.
Ejemplos: free
ping
Descripción: heramienta de red para comprobar entre otras cosas si llegamos a un host remoto.
Ejemplos: ping www.rediris.es
traceroute
Descripción: herramienta de red que nos muestra el camino que se necesita para llegar a otra maquina.
Ejemplos: traceroute www.rediris.es
du
Descripción: =disk use. uso de disco. Muestra el espacio que esta ocupado en disco.
Ejemplos: du *, du -sH /*, du -sH /etc
ifconfig
Descripción: =interface config. configuracion de interfaces de red, modems, etc.
Ejemplos: ifconfig, ifconfig eth0 ip netmask 255.255.255.0
route
Descripción: gestiona las rutas a otras redes.
Ejemplos: route, route -n
iptraf
Descripción: muestra en una aplicacion de consola TODO el trafico de red IP, UDP, ICMP.
Permite utilizar filtros, y es SUMAMENTE UTIL para diagnostico y depuracion de firewalls
Ejemplos: iptraf
tcpdump
Descripción: vuelca el contenido del trafico de red.
Ejemplos: tcpdump, tcpdump -u
lsof
Descripción: muestra los ficheros(librerias, conexiones) que utiliza cada proceso
Ejemplos: lsof, lsof -i, lsof | grep fichero
lsmod
Descripción: Muestra los modulos de kernel que estan cargados.
Ejemplos: lsmod
modprobe
Descripción: Trata de instalar un modulo, si lo encuentra lo instala pero de forma temporal.
Ejemplos: modprobe ip_tables, modprobe eepro100
rmmod
Descripción: Elimina modulos del kernel que estan cargados
Ejemplos: rmmod
sniffit
Descripción: Sniffer o husmeador de todo el trafico de red. No suele venir instalado por defecto.
Ejemplos: sniffit -i
miércoles, junio 10, 2009
Valorando el buen trabajo
¿Lo quiere rápido, barato, o bien hecho?
Puede elegir dos de las tres cosas.
.– El espectro del Titanic (Arthur C. Clarke, 1998)
martes, junio 09, 2009
Instalar Webmin en Debian
aptitude install libnet-ssleay-perl libauthen-pam-perl libio-pty-perl libmd5-perl openssl
Descargar del sitio http://www.webmin.com la ultima versión de Webmin.
wget http://prdownloads.sourceforge.net/webadmin/webmin_1.470_all.deb
Cuando se haya descargado nos ubicamos en la carpeta donde se encuentra el mismo y ejecutamos lo siguiente:
dpkg -i webmin_1.470_all.deb
Finalmente podemos acceder a la interfaz de administración del servidor por la url:
https://host:10000/
lunes, junio 08, 2009
Unix cumple 40 años
Leemos en MuyComputer que en agosto de 1969 Ken Thompson, un programador de la empresa Bell Laboratories -subsidiaria de AT&T- aprovechó la ausencia por vacaciones de su mujer y su hijo para escribir en ensamblador la primera versión de Unix. De hecho, en aquel momento ese desarrollo para el minicomputador PDP-7 de Digital Equipment Corp. (DEC) no tenía nombre, pero pronto lo bautizarían y comenzaría una evolución prodigiosa.

Unos meses antes, en marzo -como indican en un excelente repaso en ComputerWorld-, estos laboratorios renunciaron a seguir colaborando en el desarrollo de un complejo sistema de compartición de tiempo llamado Multics (Multiplexed Information and Computer Service), lo que hizo que Thompson pudiera aplicar algunos de esos principios a un desarrollo que acabaron llamando Unics, (Uniplexed en lugar de Multiplexed) como broma al anterior proyecto. Lo que no se sabe es porqué de repente de Unics se pasó a Unix directamente.
 En la imagen, un DEC PDP-7 como el que sirvió para la creación de Unix.
En la imagen, un DEC PDP-7 como el que sirvió para la creación de Unix.En 1971 Unix pasó a formar parte de la minicomputadora PDP-11, y en noviembre se publicó la primera edición del legendario “Manual de programador de Unix”, en la cual colaboraron Ken Thompson y su colega Dennis Ritchie. Este último desarrollaría en 1972 en lenguaje de programación C, que sería a la postre el pilar del desarrollo en el recién creado sistema operativo.

Thompson y Ritchie, a principios de los 70.
EN 1973 aparece por primera vez la “tubería” para comunicar dos programas, mientras que en 1974 la Universidad de California en Berkeley recibió una copia de Unix, que comenzó a conocerse en julio de ese año gracias a un artículo en la revista mensual de la ACM. El desarrollo del sistema operativo se dispararía a partir de ahí, y también la aparición de distintas versiones comerciales.

Fuente: Wikimedia Commons.
Por ejemplo, Bill Joy, recién graduado en Berkeley, creó su versión, a la que llamó BSD (Berkeley Software Distribution) y que estaba basada en el Unix V6 de Bell Labs con algunos complementos adicionales. A partir de esa primera versión BSD acabaría convirtiéndose en rival del Unix de AT&T, y de ese BSD se derivaron sistemas como FreeBSD, NetBSD, OpenBSD, DEC Ultrix, SunOS, NeXTstep/OpenStep e incluso Mac OS X.

En 1982 Bill Joy fue co-fundador de Sun Microsystems, una empresa que se basó en Sun OS para vender estaciones de trabajo y servidores. Un año más tarde aparecería la primera versión de Unix System V, que sería la base del AIX de IBM y el HP-UX de Hewlett Packard. Ese mismo año Richard Stallman anunció su intención de desarrollar un sistema operativo similar a Unix constituido por software libre.

En 1987 se daría otro evento importante: el desarrollo de Minix -un clónico limitado de Unix para entornos académicos- por parte de Andrew Tanenbaum. Ese sistema operativo sería la semilla involuntaria de la creación que un joven estudiante finlandés realizaría en 1991. Linus Torvalds comenzó el desarrollo del núcleo Linux ese año, al que complementó con varios programas GNU para lo que acabó siendo el sistema operativo GNU/Linux.

La popularidad de GNU/Linux provocó en cierta medida la caída de Unix, que hoy en día tiene una cuota de mercado muy limitada, pero aún así sigue siendo una de las referencias claves de la historia de la informática y de los sistemas operativos, sobre todo porque sus bases han sido claves para multitud de desarrollos, no sólo en el terreno de los sistemas operativos, sino en el del software en general. ¡Felicidades!
http://www.muylinux.com/2009/06/04/unix-cumple-40-anos/
OpenSolaris 2009.06, un esfuerzo notable de Sun
Recuerdo que cuando probé la primera versión de OpenSolaris me quedé bastante decepcionado y eso que la cosa prometía: el desarrollo de Sun que tenía como nombre en clave Indiana Jones estaba respaldado por Ian Murdock, una de las celebridades del mundo Linux por ser el creador y fundador de Debían.

Sin embargo aquella primera versión lanzada en mayo de 2008 fue bastante limitada tanto en sus prestaciones como en su diseño. La idea parecía brutal: tomar lo mejor de Solaris -cosas como DTrace, ZFS o sus Containers- y unirlo a lo mejor de los sistemas GNU/Linux. La evolución de este proyecto ha ido a más, y hoy ya tenemos con nosotros OpenSolaris 2009.06.

Si desean más información detallada sobre el proyecto lo mejor es que vayan a las notas de la versión, y más concretamente al excelente documento que Sun ha preparado para tratar de explicar las mejoras que nos encontramos en esta versión, que son muchas y muy importantes.
Una de ellas es el denominado Projec Crossbow que es un proyecto que permite ofrecer virtualización de red y gesitón de recursos. O sea: consolidación de la carga de servidores bajo OpenSolaris, algo muy prometedor para muchos administradores que se las ven y se las desean para gestionar sus servidores virtualizados en este apartado.
Esa mejora y otras fundamentales para los administradores se ven acompañadas por novedades para nosotros, los usuarios y frikis de sistemas operativos, que tendremos por ejemplo un sistema de control de snapshots visual y muy potente llamado Time Slider, y que para que nos hagamos una idea es una especie de Time Machine de Mac OS X que nos permite realizar backups de todo o partes del sistema para luego restaurarlas a nuestro antojo.
La gestión multimedia corre a cargo de Codeina -para la instalación de plugins y códecs- y de Elisa, y a partir de ahí el documento nos habla de diversas utilidades como una herramienta de control de tiempo (algo así como una mezcla entre una lista de tareas y un Project 2000), y sobre todo la herramienta de gestión de paquetes, Image Packaging System (IPS), que por lo visto ahora va más suave.
Yo estoy buscando el hueco -como siempre- para echarle un vistazo aunque sea en una máquina virtual, pero si alguno conoce más a fondo OpenSolaris y quere comentar algo, esta invitado a relatar sus experiencias. ¡Gracias! Por cierto: yo que ustedes tendría en cuenta que tras la compra de Sun por parte de Oracle el desarrollo de este sistema operativo podría verse comprometido.
Vía: http://www.muylinux.com/2009/06/02/opensolaris-200906-un-esfuerzo-notable-de-sun/
sábado, junio 06, 2009
Calculadora de Redes
Soy un amante de las redes IP pero una de las cosas mas cansonas de hacer es realizar los cálculos de subredes o que te digan colocala con mascara 19 y saber cual es el correspondiente en decimales o peor en binarios, nooooo eso es un carma, pero Linux te facilita la vida hasta en eso existe un paquete que se llama ipcalc, que te permite hacer todos esos engorrosos cálculos con un comando sencillicimo. Empecemos instalándolo así:
aptitude install ipcalc
y listo ahora a probarla, acá les muestro un ejemplo donde tengo una red de mascara 21, eso cual es sencillo mira esto:
 Ahora si necesitas subredes, también te las calcula y es igual de sencillo, para el ejemplo solo voy a poner un cambio de mascara a 22, lo que seria así:
Ahora si necesitas subredes, también te las calcula y es igual de sencillo, para el ejemplo solo voy a poner un cambio de mascara a 22, lo que seria así:
jueves, junio 04, 2009
Administración de máquinas Linux con Webmin
Webmin (webmin.com, paquete webmin), es una herramienta con interfaz web para la administración de sistemas Linux. Consiste en un conjunto de programas CGI escritos en Perl e incluye un servidor web que funciona con SSL (protocolo HTTPS), por lo que permite la administración remota segura de un servidor.
Tiene estructura modular, disponiendo de módulos que permiten administrar gran cantidad de aspectos del sistema: red, servidores, hardware, archivos, etc., siendo su manejo muy intuitivo. Por todo ello, es una herramienta muy utilizada y recomendable para la administración remota segura de máquinas Linux.
Webmin trae un servidor web, el daemon miniserv.pl, que arranca con el script de inicio /etc/init.d/webmin. Para acceder a Webmin teclearemos en el navegador https://localhost:10000 y haremos login con un usuario que pueda conseguir permisos de root con sudo.

Atención
El protocolo es https y no http, ya que utiliza SSL.
Los diversos módulos se organizan en el menú por temas. Desde la opción Webmin configuraremos el propio Webmin: idioma, accesos, usuarios, etc.

El módulo File manager necesita Java (paquete virtual java2-runtime).

Via: http://www.estrellateyarde.es/discover/webmin
Activar subsistema UNIX en Windows Vista
Windows Vista SP1, al igual que Windows 2003 R2 y Windows 2008 Server, dispone de una característica poco conocida pero que es muy conveniente conocer, sobre todo para desarrolladores y administradores de UNIX.
Se trata de SUA (Subsistem for UNIX Applications), un subsistema basado en Interix que permite correr nativamente aplicaciones para UNIX/Linux en los sistemas operativos windows que lo implementen.
Para activarlo, basta con ir a agregar programas y características, del panel de control y activarlo allí.

Accediendo luego por SSH, te puedes manejar como en un sistema UNIX Like.
El error historico de Microsoft
Este articulo -que me parecio muy interesante, para entender porque Guindows con el tiempo se va haciendo mas lento, esta tomado de http://librodenotas.com y fue escrito por el Dr. Francisco Serradilla.
Espero lo disfruten.
El error histórico de Microsoft
En MS-DOS, como en UNIX, como en VMS, las aplicaciones se instalaban en un directorio, en el que uno colocaba todos los ejecutables, librerías, archivos de configuración, ficheros de datos, etc. que necesitara el programa para su funcionamiento. Esta metodología era bastante limpia porque permitía tener todo lo necesario en un único lugar del disco. MS-DOS era monousuario y monotarea, es decir, no había más que un usuario en el sistema (más bien el concepto de usuario no existía) y sólo podía ejecutar una aplicación en cada momento. Por tanto sólo había una configración posible, y bastaba con guardar la configuración en un archivo dentro del mismo directorio del programa. Si además la aplicación generaba documentos, como sucede por ejemplo con un procesador de texto, éstos podían guardarse en el mismo directorio también o, mejor, en otro diferente, lo que facilitaba la realización de copias de seguridad.
UNIX (antepasado de linux, por decirlo rápido aunque mal) fue desde el principio un sistema multiusuario y multitarea, de modo que tenía que resolver el problema de cómo guardar la configuración personal de cada usuario para cada programa. Para eso se ideó un tipo especial de archivo, cuyos nombres comenzaban por punto (.) que no aparecía por defecto al mirar los contenidos de un directorio; además cada usuario tenía (tiene) un directorio personal donde guardar sus archivos, incluídos los de configuración.
Este sistema tan simple tiene algunas ventajas que pasan desapercibidas sin una reflexión detenida. Por ejemplo, el tema de los permisos. Un usuario jamás tiene por qué tener permisos de escritura en el directorio donde está el programa con “sus cosas”. Sólo tiene que tener permiso de escritura en sus archivos y sus configuraciones, que cuelgan todos a partir de su directorio de usuario (en linux es /home/nombre-del-usuario). La otra ventaja es que un usuario no tiene por qué tener permiso de lectura (y mucho menos de modificación) de los directorios de los otros usuarios.
Cuando Microsoft desarrolló Windows tuvo que enfrentarse a nuevos problemas, para los que posiblemente reflexionó poco. Y alguna mente privilegiada de redmon pensó: “creemos el win.ini”, un archivo donde guardar la configuración de Windows. Y más adelante ¿por qué no creamos un servicio en el API de Windows para que los desarrolladores añadan la configuración de sus propios programas al win.ini, y así centralizamos todo? Hay que pensar que en su primera época Windows todavía era monousuario y su sistema de archivos (FAT) no permitía asignar permisos a los ficheros.
La cosa se complicó cuando llegó la idea multiusuario a Windows. El win.ini ya no servía, PORQUE SÓLO HABÍA UNO, y diferentes usuarios querían tener diferentes configuraciones. Para mayor desastre los desarrolladores se habían acostumbrado a meter sus configuraciones en el win.ini. Así que la misma mente privilegiada de redmon (u otra todavía más impresionante) dijo ¡Hágase el registro! El registro es una especie de base de datos donde se guardan todo tipo de configuraciones de hardware, de Windows, de programas y de usuario. Todo mezclado, como en el cambalache de Discépolo.
Más adelante (con Windows NT y luego con XP) se introdujo un nuevo sistema de archivos (NTFS) que permitía permisos en los ficheros, y se creó una infraestructura para que cada usuario tuviera su espacio propio, pero ya era demasiado tarde. El registro se había convertido en un auténtico monstruo, una estructura que crece en las máquinas Windows hasta el tamaño de muchos MB y es el verdadero culpable de que los Windows se vuelvan lentos como tortugas en el arranque al cabo de unos meses de uso.
Otra consecuencia sorprendente: un usuario de linux, o de Apple (puesto que MacOS está construído sobre UNIX) es que en estos sistemas se puede instalar un programa, en general, copiando los archivos a cualquier lado (aunque haya un sitio recomendado para colocarlos) y los programas FUNCIONAN sin más. En Windows, como todo el mundo sabe, esto no es posible (salvo casos muy raros, normalmente en programas que vienen del mundo linux). Los programas hay que INSTALARLOS. ¿Por qué? Sencillamente porque además de copiar archivos tienen que meter cosas en el registro.
Lo peor es que ya es demasiado tarde para cambiar los hábitos de los usuarios y los desarrolladores. Todo el mundo es capaz de escribir en el registro y muchísimos programas suponen que pueden escribir donde les parezca: por eso es tan fácil para un virus instalarse en el sistema. Con Windows Vista han hecho un tímido intento de prohibir por defecto y pedir permiso cuando alguien intenta escribir en el registro o en los directorios del sistema, pero las preguntas son tan frecuentes que los usuarios simplemente desactivan esa opción. Y vuelven a estar expuestos.
Es un desastre.
25 de septiembre de 2007
miércoles, junio 03, 2009
Dar permisos en GNU/Linux con chmod
Muchas veces emos visto que damos permisos a archivos por seguridad e incliso en algunos post eh usado el comando chmod para poder ejecutar algo.
Este comando se aplica sobre ficheros o carpetas, en el caso de que sean carpetas podemos usar la opcion -R para dar permisos recursivamente a todas las carpetas y ficheros que contenga recursivamente. En cuanto a la sintaxis del comando, podemos decir que responde a
chmod [opciones] XXX nomFichero/nomCarpeta
donde en opciones podemos expecificar por ejemplo cosas como -R, XXX es el número de permisos tal y como especificamos a continuación:
Relación Numérica con los Permisos
0 = Ningún permiso (Lectura = 0 + Escritura = 0 + Ejecución = 0)
1 = Permiso de Ejecución (Lectura = 0 + Escritura = 0 + Ejecución = 1)
2 = Permiso de Escritura (Lectura = 0 + Escritura = 2 + Ejecución = 0)
3 = Permiso de Escritura y Ejecución (Lectura = 0, Escritura = 2, Ejecución = 1)
4 = Permiso de Lectura (Lectura = 4 + Escritura = 0 + Ejecución = 0)
5 = Permiso de Lectura y Ejecución (Lectura = 4 + Escritura = 0 + Ejecución = 1)
6 = Permiso de Lectura y Escritura (Lectura = 4 + Escritura = 2 + Ejecución = 0)
7 = Permiso de Lectura, Escritura y Ejecución (Lectura = 4 + Escritura2 + Ejecución = 1) =
Luego, por cada Identidad, podemos obtener un número comprendido entre 0 y 7, que delimitarán por Identidad, claramente, sus privilegios en particular sobre un archivo o carpeta.
¿Entonces, que es, por ejemplo, chmod 644?
Son los Permisos que tiene asignados cada Identidad, sobre un archivo o carpeta, según su Relación Numérica. Siempre siguiendo este orden:
Propietario = 6 (Puede Leer y Escribir)
Grupo = 4 (solo puede Leer)
Otros = 4 (solo puede Leer)
Nota: Evidentemente el comando chmod contiene muchas más opciones y formas de asignar permisos, puedes consultarlas consultando el manual del comando, para ello abre un terminal y teclea:
man chmod
El número de los permisos no está decidido al azar, sino que se basa en reglas binarias, tal y como nos detalla en su comentario:
La “regla” de los números quedaría mejor explicado y entendible si la explicas en binario:
// el 1 activa el permiso, el 0 lo apaga
Lectura escritura ejecución
0 0 0 = 0
0 0 1 = 1
0 1 0 = 2
0 1 1 = 3
1 0 0 = 4
1 0 1 = 5
1 1 0 = 6
1 1 1 = 7
Pues eso, para los que no entendiesen la relación, que vean que no está hecha al azar, si no que tiene su por qué y así no te lo tienes que aprender de memoria y nunca se te olvida
Otra manera mas intuitiva podemos usar las letras w = Writer, r= read y x=execute de escritura, lectura y ejecucion y como aditivo "+" y sustractivo "-".
entonces para identificar a quien estamos dando el permiso podemos usar g=grupo y o=otros.
De esa manera estaremos usando el cmado de la siguiente manera:
$ chmod [responzable][operador][permiso] archivo/carpeta
Ejemplo:
chmod +x archivo/carpeta (estamos dando permiso de ejecucion al propietario sobre el archivo o carpeta especificada)
chmod g-w archivo/carpeta (estamos quitando permiso de escritura al grupo sobre el archivo o carpeta especificada)
chmod o+r archivo/carpeta (estamos dando permiso de lectura a los otros usuarios sobre el archivo o carpeta especificada)
Suscribirse a:
Entradas (Atom)


